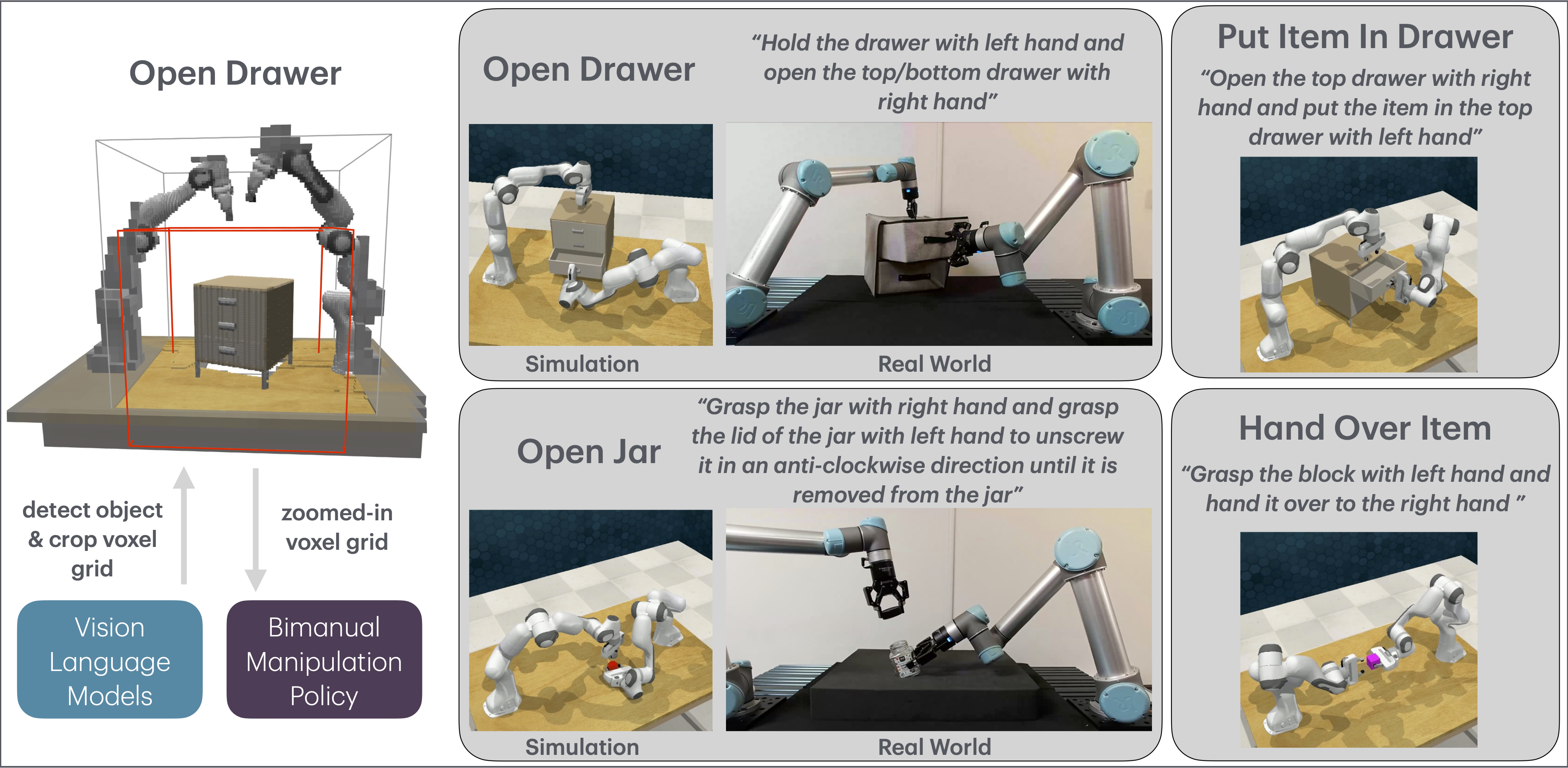
Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world Open Drawer and Open Jar tasks using two UR5s.
Bimanual manipulation is essential for robotics tasks, such as when objects are too large to be controlled by one gripper, or when one arm stabilizes an object of interest to make it simpler for the other arm to manipulate. In this work, we focus on asymmetric bimanual manipulation. Here, "asymmetry" refers to the functions of the two arms, where one is a stabilizing arm, while the other is the acting arm. Asymmetric tasks are common in household and industrial settings, such as cutting food, opening bottles, and packaging boxes. They typically require two-hand coordination and high-precision, fine-grained manipulation, which are challenging for current robotic manipulation systems. To tackle bimanual manipulation, some methods train policies on large datasets, and some exploit primitive actions. However, they are generally sample inefficient, and using primitives can hinder generalization to different tasks.
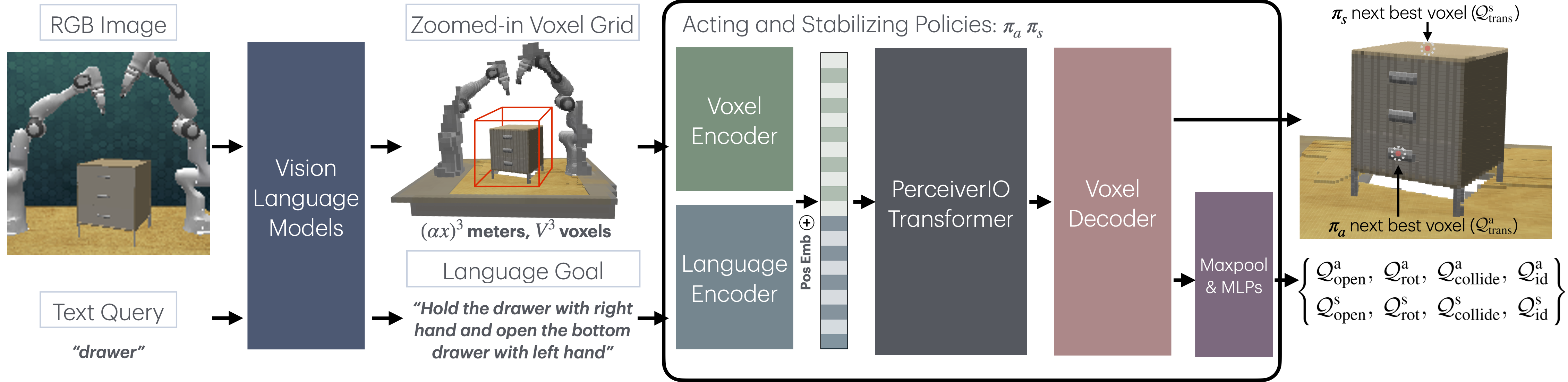
To this end, we propose VoxAct-B, a novel voxel-based, language-conditioned method for bimanual manipulation. Voxel representations, when coupled with discretized action spaces, can increase sample efficiency and generalization by introducing spatial equivariance into a learned system, where transformations of the input lead to corresponding transformations of the output. However, processing voxels is computationally demanding. To address this, we propose utilizing VLMs to focus on the most pertinent regions within the scene by cropping out less relevant regions. This substantially reduces the overall physical dimensions of the areas used to construct a voxel grid, enabling an increase in voxel resolution without incurring computational costs. To our knowledge, this is the first study to apply voxel representations in bimanual manipulation.
We also employ language instructions and VLMs to determine the roles of each arm: whether they are acting or stabilizing. For instance, in a drawer-opening task, the orientation of the drawer and the position of the handle affect which arm is more suitable for opening the drawer (acting) and which is better for holding it steady (stabilizing). We use VLMs to compute the pose of the object of interest relative to the front camera and to decide the roles of each arm. Then, we provide appropriate language instructions to the bimanual manipulation policy to control the acting and stabilizing arms.
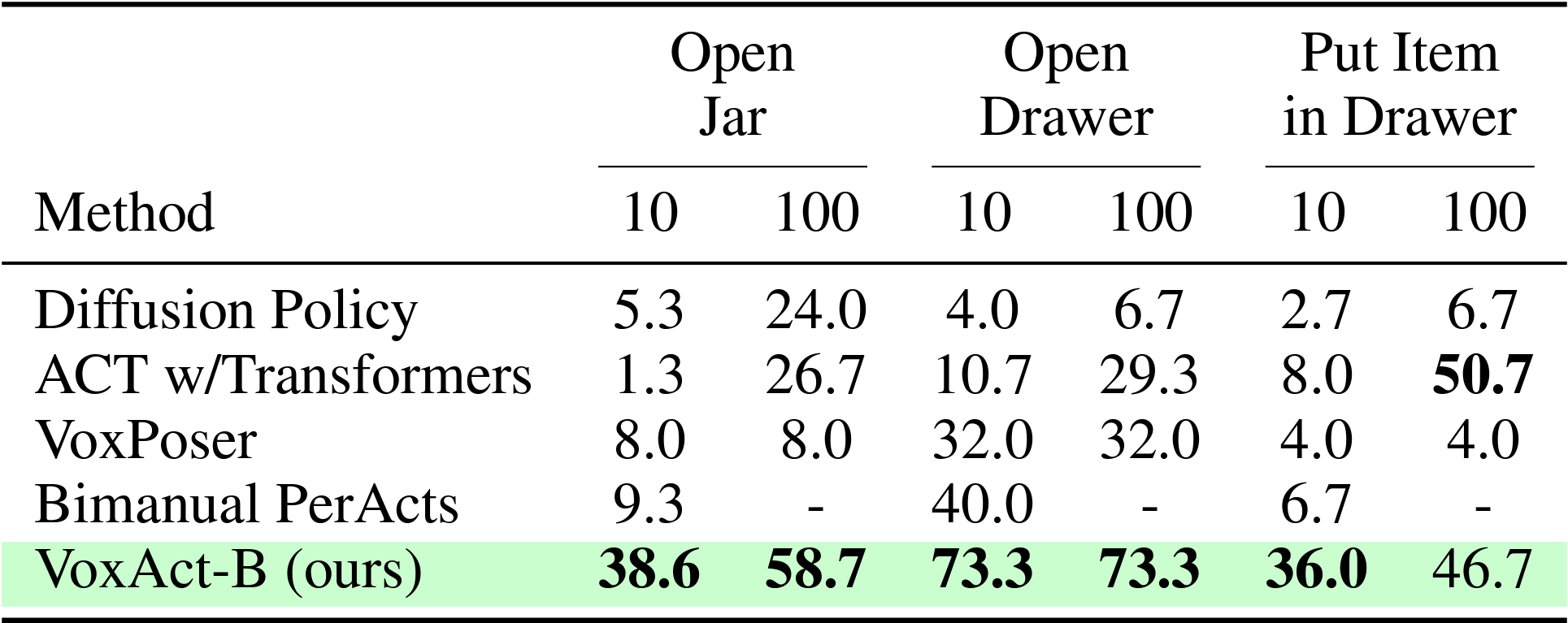
With 10 training demonstrations, VoxAct-B outperforms all baselines by a large margin. When we train all methods using more demonstrations (100), VoxAct-B still outperforms all baselines. Qualitatively, baseline methods, especially VoxPoser, typically struggle with precisely grasping objects such as drawer handles and jars. The baselines also struggle with correctly assigning the roles of each arm. For instance, a policy intended to execute acting actions may unpredictably produce stabilizing actions. Furthermore, they can generate kinematically infeasible actions or actions that lead to erratic movements, as seen in ACT and Diffusion Policy, which may be caused by insufficient training data. In contrast, we observe fewer of these errors with VoxAct-B.
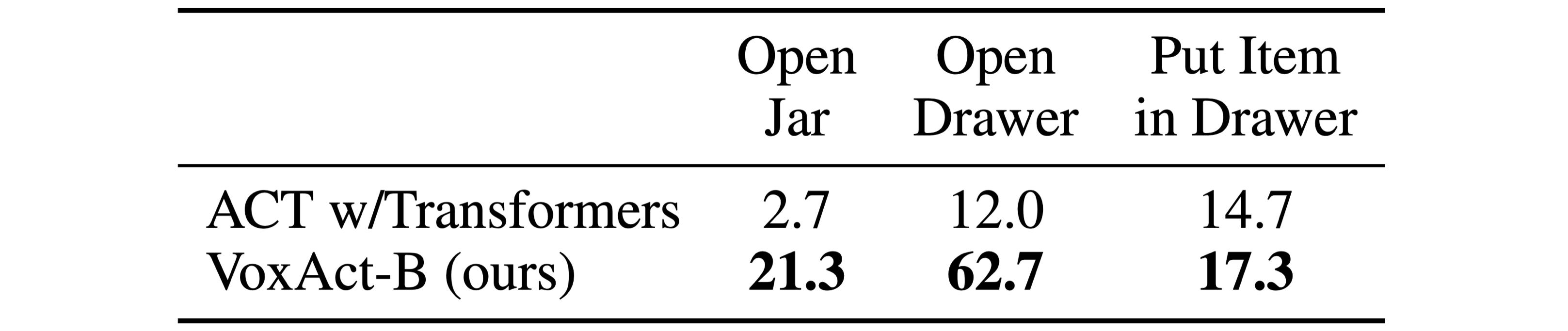
We train a single policy of ACT and VoxAct-B on Open Jar, Open Drawer, and Put Item in Drawer, with 10 demonstrations for each task. For evaluation, both methods use the checkpoint with the best average validation success rate across all tasks. We use the same validation and test data as the baseline comparison.
All videos, except those in the failure sections, are categorized as successes.
@inproceedings{liu2024voxactb,
title={VoxAct‐B: Voxel‐Based Acting and Stabilizing Policy for Bimanual Manipulation},
author={I-Chun Arthur Liu and Sicheng He and Daniel Seita and Gaurav S. Sukhatme},
booktitle={Conference on Robot Learning},
year={2024}
}